Using Embedded Cluster
This topic describes how to use the Replicated Embedded Cluster to configure, install, and manage your application in an embedded Kubernetes cluster.
If you are instead looking for information about creating Kubernetes Installers with Replicated kURL, see the Replicated kURL section.
Overview
Replicated Embedded Cluster allows you to distribute a Kubernetes cluster and your application together as a single appliance, making it easy for enterprise users to install, update, and manage the application and the cluster in tandem. Embedded Cluster is based on the open source Kubernetes distribution k0s. For more information, see the k0s documentation.
For software vendors, Embedded Cluster provides a Config for defining characteristics of the cluster that will be created in the customer environment. Additionally, each version of Embedded Cluster includes a specific version of Replicated KOTS, ensuring compatibility between KOTS and the cluster. For enterprise users, cluster updates are done automatically at the same time as application updates, allowing users to more easily keep the cluster up-to-date without needing to use kubectl.
The following diagram demonstrates how Kubernetes and an application are installed into a customer environment using Embedded Cluster:
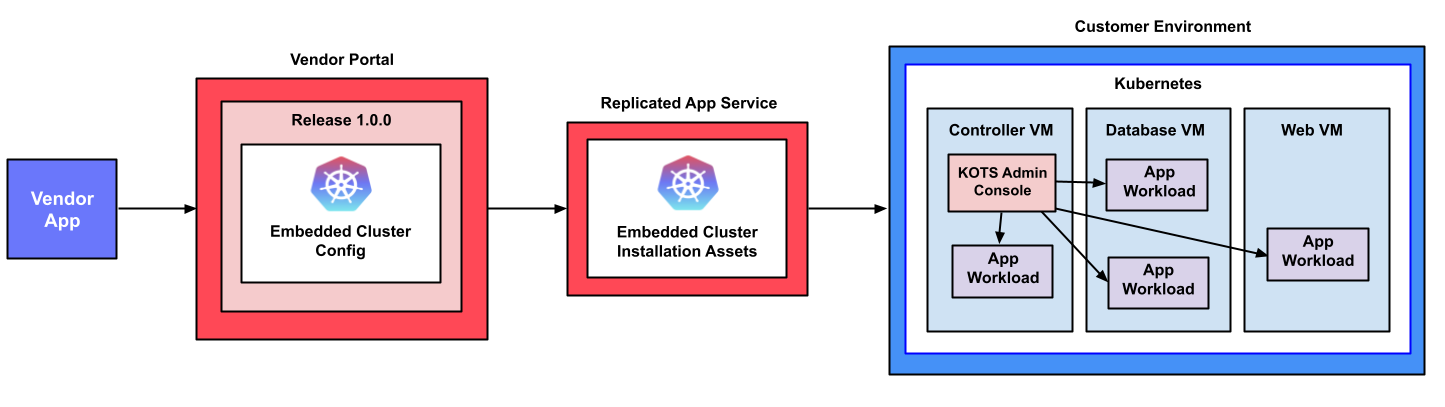
View a larger version of this image
As shown in the diagram above, the Embedded Cluster Config is included in the application release in the Replicated Vendor Portal and is used to generate the Embedded Cluster installation assets. Users can download these installation assets from the Replicated app service (replicated.app) on the command line, then run the Embedded Cluster installation command to install Kubernetes and the KOTS Admin Console. Finally, users access the Admin Console to optionally add nodes to the cluster and to configure and install the application.
Comparison to kURL
Embedded Cluster is a successor to Replicated kURL. Compared to kURL, Embedded Cluster offers several improvements such as:
- Significantly faster installation, updates, and node joins
- A redesigned Admin Console UI for managing the cluster
- Improved support for multi-node clusters
- One-click updates of both the application and the cluster at the same time
Requirements
System Requirements
-
Linux operating system
-
x86-64 architecture
-
systemd
-
At least 2GB of memory and 2 CPU cores
-
The filesystem at
/var/lib/embedded-clusterhas 40Gi or more of total space and must be less than 80% fullnoteThe directory used for data storage can be changed by passing the
--data-dirflag with the Embedded Cluster install command. For more information, see Embedded Cluster Install Command Options.Note that in addition to the primary
/var/lib/embedded-clusterdirectory, Embedded Cluster creates directories and files in the following locations:/etc/cni/etc/k0s/opt/cni/opt/containerd/run/calico/run/containerd/run/k0s/sys/fs/cgroup/kubepods/sys/fs/cgroup/system.slice/containerd.service/sys/fs/cgroup/system.slice/k0scontroller.service/usr/libexec/k0s/var/lib/calico/var/lib/cni/var/lib/containers/var/lib/kubelet/var/log/calico/var/log/containers/var/log/pods/usr/local/bin/k0s
-
(Online installations only) Access to replicated.app and proxy.replicated.com or your custom domain for each
-
Embedded Cluster is based on k0s, so all k0s system requirements and external runtime dependencies apply. See System requirements and External runtime dependencies in the k0s documentation.
Port Requirements
Embedded Cluster requires that the following ports are open and available:
- 2379/TCP *
- 2380/TCP
- 4789/UDP
- 6443/TCP
- 7443/TCP
- 9091/TCP
- 9099/TCP *
- 9443/TCP
- 10248/TCP *
- 10249/TCP
- 10250/TCP
- 10256/TCP
- 10257/TCP *
- 10259/TCP *
- 30000/TCP ***
- 50000/TCP * ** ***
* These ports are used only by processes running on the same node. Ensure that there are no other processes using them. It is not necessary to create firewall openings for these ports.
** Required for air gap installations only.
*** By default, the Admin Console and Local Artifact Mirror (LAM) run on ports 30000 and 50000, respectively. If these ports are occupied, you can select different ports during installation. For more information, see Embedded Cluster Install Command Options.
Limitations
Embedded Cluster has the following limitations:
-
No automated migration from kURL: There is no automated migration from an existing kURL instance to Embedded Cluster. For a manual migration procedure, reach out to Alex Parker at alexp@replicated.com.
-
Multi-node support is in beta: Support for multi-node embedded clusters is in beta, and enabling high availability for multi-node clusters is in alpha. Only single-node embedded clusters are generally available. For more information, see Add Nodes (Beta) and Enable High Availability for Multi-Node Clusters (Alpha) below.
-
Disaster recovery is in alpha: Disaster Recovery for Embedded Cluster installations is in alpha. For more information, see Disaster Recovery for Embedded Cluster (Alpha).
-
Partial rollback support: Rollbacks for Embedded Cluster installations are supported only when rolling back to a version where there is no change to the Embedded Cluster Config compared to the currently-installed version. For example, users can roll back to release version 1.0.0 after upgrading to 1.1.0 only if both 1.0.0 and 1.1.0 use the same Embedded Cluster Config.
-
Changing node hostnames is not supported: After a host is added to a Kubernetes cluster, Kubernetes assumes that the hostname and IP address of the host will not change. If you need to change the hostname or IP address of a node, you must first remove the node from the cluster. For more information about the requirements for naming nodes, see Node name uniqueness in the Kubernetes documentation.
-
Automated installations not supported: Users cannot do automated (headless) Embedded Cluster installations because it is not possible to configure the application by passing the ConfigValues file with the installation command. Embedded Cluster installations require that the application is configured from the Admin Console config screen. For more information about automating existing cluster or kURL installations with the KOTS CLI, see Installing with the CLI.
-
Automatic updates not supported: Configuring automatic updates from the Admin Console so that new versions are automatically deployed is not supported for Embedded Cluster installations. For more information, see Configuring Automatic Updates.
-
Embedded Cluster installation assets not available through the Download Portal: The assets required to install with Embedded Cluster cannot be shared with users through the Download Portal. Users can follow the Embedded Cluster installation instructions to download and extract the installation assets. For more information, see Online Installation with Embedded Cluster.
-
minKotsVersionandtargetKotsVersionnot supported: TheminKotsVersionandtargetKotsVersionfields in the KOTS Application custom resource are not supported for Embedded Cluster installations. This is because each version of Embedded Cluster includes a particular version of KOTS. SettingtargetKotsVersionorminKotsVersionto a version of KOTS that does not coincide with the version that is included in the specified version of Embedded Cluster will cause Embedded Cluster installations to fail with an error message like:Error: This version of App Name requires a different version of KOTS from what you currently have installed. To avoid installation failures, do not use targetKotsVersion or minKotsVersion in releases that support installation with Embedded Cluster. -
Support bundles over 100MB in the Admin Console: Support bundles are stored in rqlite. Bundles over 100MB could cause rqlite to crash, causing errors in the installation. You can still generate a support bundle with the CLI following the instructions here.
-
Kubernetes version template functions not supported: The KOTS KubernetesVersion, KubernetesMajorVersion, and KubernetesMinorVersion template functions do not provide accurate Kubernetes version information for Embedded Cluster installations. This is because these template functions are rendered before the Kubernetes cluster has been updated to the intended version. However,
KubernetesVersionis not necessary for Embedded Cluster because vendors specify the Embedded Cluster version, which includes a known Kubernetes version. -
Custom domains not supported: Embedded Cluster does not support the use of custom domains, even if custom domains are configured. We intend to add support for custom domains. For more information about custom domains, see About Custom Domains.
-
KOTS Auto-GitOps workflow not supported: Embedded Cluster does not support the KOTS Auto-GitOps workflow. If an end-user is interested in GitOps, consider the Helm install method instead. For more information, see Installing with Helm.
-
Downgrading Kubernetes not supported: Embedded Cluster does not support downgrading Kubernetes. The admin console will not prevent end-users from attempting to downgrade Kubernetes if a more recent version of your application specifies a previous Embedded Cluster version. You must ensure that you do not promote new versions with previous Embedded Cluster versions.
-
Templating not supported in Embedded Cluster Config: The Embedded Cluster Config resource does not support the use of Go template functions, including KOTS template functions.
-
Policy enforcement on Embedded Cluster workloads is not supported: The Embedded Cluster runs workloads that require higher levels of privilege. If your application installs a policy enforcement engine such as Gatekeeper or Kyverno, ensure that its policies are not enforced in the namespaces used by Embedded Cluster.
-
Installing on STIG- and CIS-hardened OS images is not supported: Embedded Cluster isn't tested on these images, and issues have arisen when trying to install on them.
Quick Start
You can use the following steps to get started quickly with Embedded Cluster. More detailed documentation is available below.
-
Create a new customer or edit an existing customer and select the Embedded Cluster Enabled license option. Save the customer.
-
Create a new release that includes your application. In that release, create an Embedded Cluster Config that includes, at minimum, the Embedded Cluster version you want to use. See the Embedded Cluster GitHub repo to find the latest version.
Example Embedded Cluster Config:
apiVersion: embeddedcluster.replicated.com/v1beta1
kind: Config
spec:
version: 1.16.0+k8s-1.30 -
Save the release and promote it to the channel the customer is assigned to.
-
Return to the customer page where you enabled Embedded Cluster. At the top right, click Install instructions and choose Embedded Cluster. A dialog appears with instructions on how to download the Embedded Cluster installation assets and install your application.

-
On your VM, run the commands in the Embedded Cluster install instructions dialog.
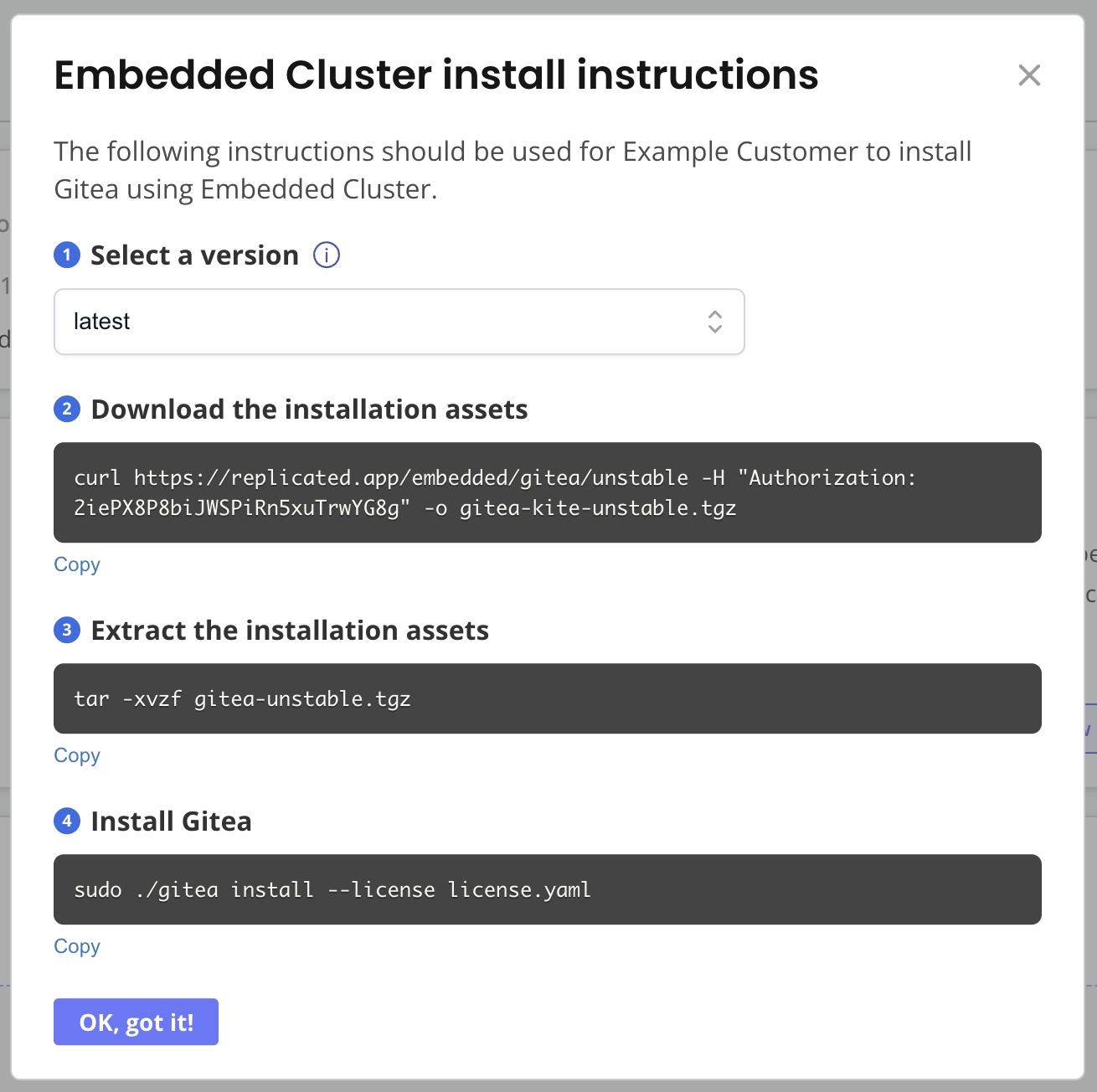
-
Enter an Admin Console password when prompted.
The Admin Console URL is printed when the installation finishes. Access the Admin Console to begin installing your application. During the installation process in the Admin Console, you have the opportunity to add nodes if you want a multi-node cluster. Then you can provide application config, run preflights, and deploy your application.
About Configuring Embedded Cluster
To install an application with Embedded Cluster, an Embedded Cluster Config must be present in the application release. The Embedded Cluster Config lets you define several characteristics about the cluster that will be created.
For more information, see Embedded Cluster Config.
About Installing with Embedded Cluster
This section provides an overview of installing applications with Embedded Cluster.
Installation Options
Embedded Cluster supports installations in online (internet-connected) environments and air gap environments with no outbound internet access.
For online installations, Embedded Cluster also supports installing behind a proxy server.
For more information about how to install with Embedded Cluster, see:
Customer-Specific Installation Instructions
To install with Embedded Cluster, you can follow the customer-specific instructions provided on the Customer page in the Vendor Portal. For example:
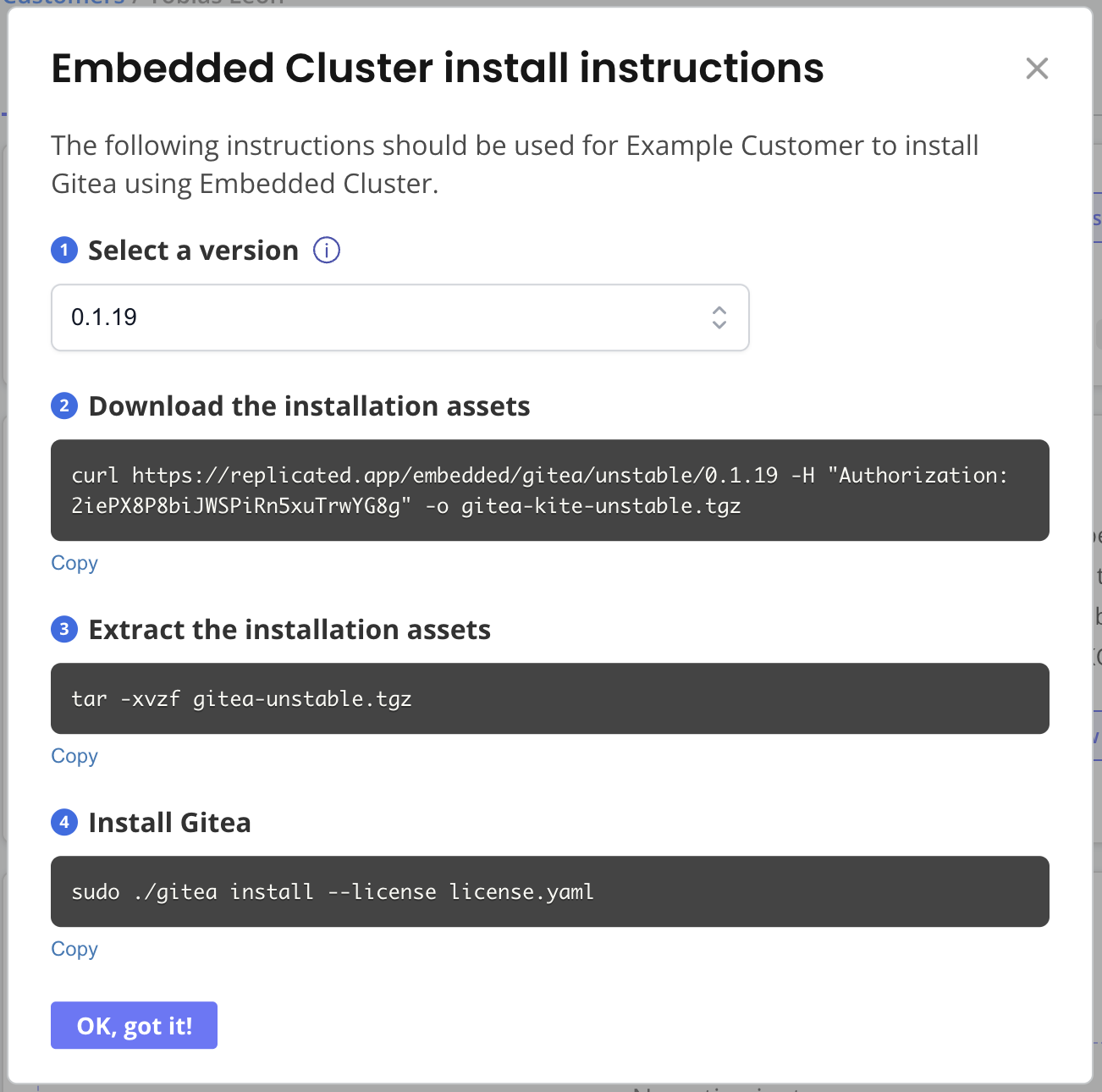
View a larger version of this image
About Host Preflight Checks
During installation, Embedded Cluster automatically runs a default set of host preflight checks. The default host preflight checks are designed to verify that the installation environment meets the requirements for Embedded Cluster, such as:
- The system has sufficient disk space
- The system has at least 2G of memory and 2 CPU cores
- The system clock is synchronized
For Embedded Cluster requirements, see Requirements. For the full default host preflight spec for Embedded Cluster, see host-preflight.yaml in the embedded-cluster repository in GitHub.
If any of the host preflight checks fail, installation is blocked and a message describing the failure is displayed. For more information about host preflight checks for installations on VMs or bare metal servers, see About Host Preflights.
Limitations
Embedded Cluster host preflight checks have the following limitations:
- The default host preflight checks for Embedded Cluster cannot be modified, and vendors cannot provide their own custom host preflight spec for Embedded Cluster.
- Host preflight checks do not check that any application-specific requirements are met. For more information about defining preflight checks for your application, see Defining Preflight Checks.
Skip Host Preflight Checks
You can skip host preflight checks by passing the --skip-host-preflights flag with the Embedded Cluster install command. For example:
sudo ./my-app install --license license.yaml --skip-host-preflights
When you skip host preflight checks, the Admin Console still runs any application-specific preflight checks that are defined in the release before the application is deployed.
Skipping host preflight checks is not recommended for production installations.
(Optional) Serve Installation Assets Using the Vendor API
To install with Embedded Cluster, you need to download the Embedded Cluster installer binary and a license. Air gap installations also require an air gap bundle. Some vendors already have a portal where their customers can log in to access documentation or download artifacts. In cases like this, you can serve the Embedded Cluster installation essets yourself using the Replicated Vendor API, rather than having customers download the assets from the Replicated app service using a curl command during installation.
To serve Embedded Cluster installation assets with the Vendor API:
-
If you have not done so already, create an API token for the Vendor API. See Using the Vendor API v3.
-
Call the Get an Embedded Cluster release endpoint to download the assets needed to install your application with Embedded Cluster. Your customers must take this binary and their license and copy them to the machine where they will install your application.
Note the following:
-
(Recommended) Provide the
customerIdquery parameter so that the customer’s license is included in the downloaded tarball. This mirrors what is returned when a customer downloads the binary directly using the Replicated app service and is the most useful option. Excluding thecustomerIdis useful if you plan to distribute the license separately. -
If you do not provide any query parameters, this endpoint downloads the Embedded Cluster binary for the latest release on the specified channel. You can provide the
channelSequencequery parameter to download the binary for a particular release.
-
About Performing Updates with Embedded Cluster
When you update an application installed with Embedded Cluster, you update both the application and the cluster infrastructure together, including Kubernetes, KOTS, and other components running in the cluster. There is no need or mechanism to update the infrastructure on its own.
When you deploy a new version, any changes to the cluster are deployed first. The Admin Console waits until the cluster is ready before updatng the application.
Any changes made to the Embedded Cluster Config, including changes to the Embedded Cluster version, Helm extensions, and unsupported overrides, trigger a cluster update.
When performing an upgrade with Embedded Cluster, the user is able to change the application config before deploying the new version. Additionally, the user's license is synced automatically. Users can also make config changes and sync their license outside of performing an update. This requires deploying a new version to apply the config change or license sync.
For more information about updating, see Performing Updates with Embedded Cluster.
Access the Cluster
With Embedded Cluster, end-users are rarely supposed to need to use the CLI. Typical workflows, like updating the application and the cluster, are driven through the Admin Console.
Nonetheless, there are times when vendors or their customers need to use the CLI for development or troubleshooting.
To access the cluster and use other included binaries:
-
SSH onto a controller node.
-
Use the Embedded Cluster shell command to start a shell with access to the cluster:
sudo ./APP_SLUG shellThe output looks similar to the following:
__4___
_ \ \ \ \ Welcome to APP_SLUG debug shell.
<'\ /_/_/_/ This terminal is now configured to access your cluster.
((____!___/) Type 'exit' (or CTRL+d) to exit.
\0\0\0\0\/ Happy hacking.
~~~~~~~~~~~
root@alex-ec-2:/home/alex# export KUBECONFIG="/var/lib/embedded-cluster/k0s/pki/admin.conf"
root@alex-ec-2:/home/alex# export PATH="$PATH:/var/lib/embedded-cluster/bin"
root@alex-ec-2:/home/alex# source <(kubectl completion bash)
root@alex-ec-2:/home/alex# source /etc/bash_completionThe appropriate kubeconfig is exported, and the location of useful binaries like kubectl and Replicated’s preflight and support-bundle plugins is added to PATH.
noteYou cannot run the
shellcommand on worker nodes. -
Use the available binaries as needed.
Example:
kubectl versionClient Version: v1.29.1
Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3
Server Version: v1.29.1+k0s -
Type
exitor Ctrl + D to exit the shell.noteIf you encounter a typical workflow where your customers have to use the Embedded Cluster shell, reach out to Alex Parker at alexp@replicated.com. These workflows might be candidates for additional Admin Console functionality.
Manage Nodes
The section describes managing nodes in clusters created with Embedded Cluster, including how to add or reset nodes.
Add Nodes (Beta)
You can add nodes and create a multi-node cluster. When adding nodes, you select one or more roles for that node, depending on which roles are defined in the Embedded Cluster config. The Admin Console provides the join command you use to join nodes to the cluster.
For more information about defining node roles, see Roles in Embedded Cluster Config.
To add nodes to a cluster:
-
In the Admin Console, click Cluster Management at the top.
When initially installing the application, you are brought to this page automatically after logging into the Admin Console.
-
Click Add node.
-
In the Add a Node dialog, select one or more roles for this node. If no custom roles are defined, the role selection will not appear and only the join command will show.
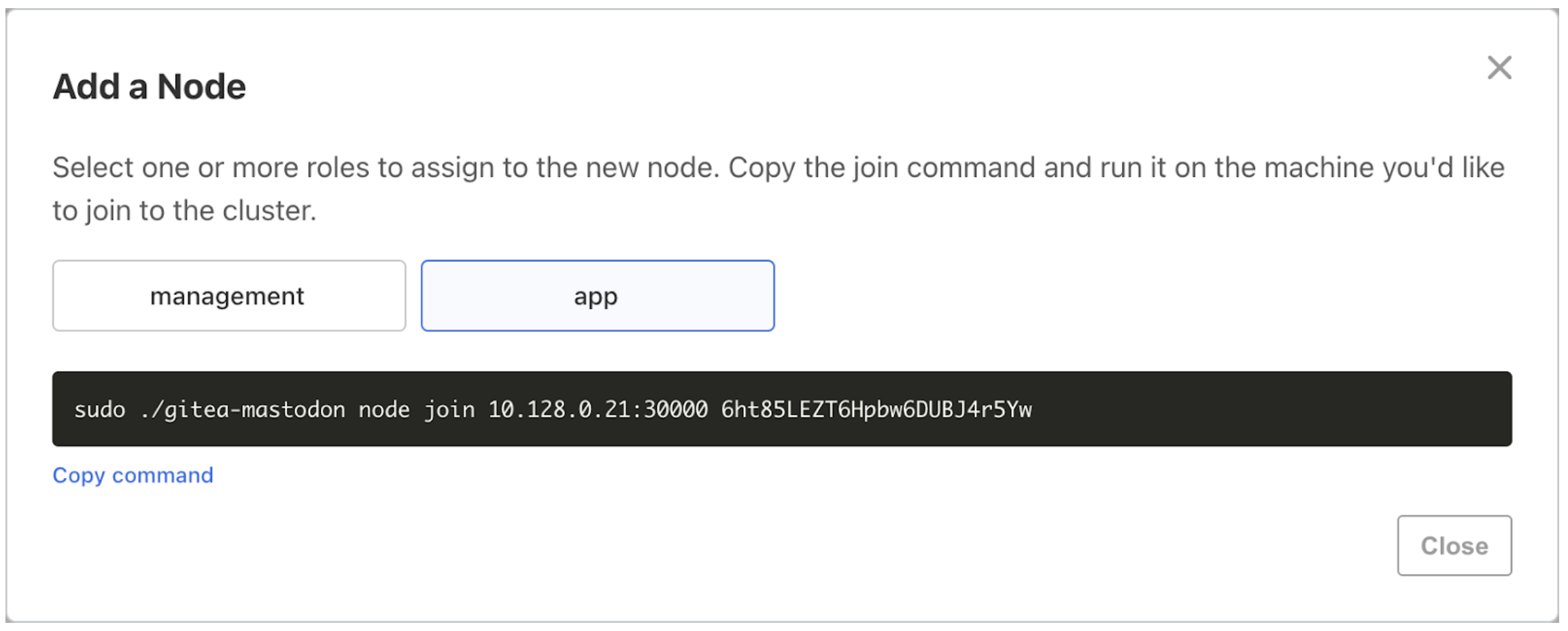
-
Copy the provided join command.
Example:
sudo ./APP_SLUG join 10.128.0.43:30000 bM8DO3MNvkouz9TFK3TcFanI -
SSH onto the machine you want to join to the cluster. Ensure that the Embedded Cluster binary is available on that node. For more information about downloading Embedded Cluster installation assets, see Online Installation with Embedded Cluster.
importantYou must join nodes with the same installer that you used for the first node. If you use a different installer from a different release of your application, the cluster will not be stable.
-
Run the copied join command using the Embedded Cluster binary.
-
Check the Cluster Management page in the Admin Console to see the node appear and wait for the status to change to Ready.
-
Repeat the process for as many nodes as you would like to add.
Enable High Availability for Multi-Node Clusters (Alpha)
Multi-node clusters are not highly available by default. The first node of the cluster is special and holds important data for Kubernetes and KOTS, such that the loss of this node would be catastrophic for the cluster. After three controller nodes are present in the cluster, high availability (HA) can be enabled.
High availability for Embedded Cluster in an Alpha feature. This feature is subject to change, including breaking changes. To get access to this feature, reach out to Alex Parker at alexp@replicated.com.
Requirement
High availability is supported with Embedded cluster version 1.4.1 or later
Create a Multi-Node HA Cluster
To create a multi-node HA cluster:
-
Set up a cluster with at least two controller nodes. You can do an online (internet-connected) or air gap installation. For online clusters, see Add Nodes (Alpha) above. For air gap clusters, see Air Gap Installation with Embedded Cluster.
-
SSH onto a third node that you want to join to the cluster as a controller.
-
Run the join command and pass the
--enable-haflag. For example:sudo ./APP_SLUG join `--enable-ha` 10.128.0.80:30000 tI13KUWITdIerfdMcWTA4Hpf -
After the third node joins the cluster, type
yin response to the prompt asking if you want to enable high availability. -
Wait for the migration to complete.

Limitations
-
Support bundles are now stored in rqlite instead of MinIO because MinIO is no longer deployed. We’ve successfully stored 100 MB support bundles (which is much larger than most support bundles), but bundles over 100 MB can cause rqlite to crash and restart. We are considering making support bundles ephemeral instead of storing them to address this issue, because support bundles are rarely needed long after they’re generated.
-
The
--enable-haflag serves as a feature flag during the Alpha phase. In the future, the prompt about migrating to high availability will display automatically if the cluster is not yet HA and you are adding the third or more controller node.
Reset a Node
Resetting a node removes the cluster and your application from that node. This is useful for iteration, development, and when mistakes are made, so you can reset a machine and reuse it instead of having to procure another machine.
If you want to completely remove a cluster, you need to reset each node individually.
When resetting a node, OpenEBS PVCs on the node are deleted. Only PVCs created as part of a StatefulSet will be recreated automatically on another node. To recreate other PVCs, the application will need to be redeployed.
To reset the node of a cluster:
-
SSH onto the machine. Ensure that the Embedded Cluster binary is still available on that machine. For more information about downloading Embedded Cluster installation assets, see Online Installation with Embedded Cluster.
-
Run the reset command to reset the node. The
--rebootflag automatically reboots the machine to ensure that transient configuration is also reset.sudo ./APP_SLUG reset --rebootnotePass the
--no-promptflag to disable interactive prompts. Pass the--forceflag to ignore any errors encountered during the reset.
Additional Use Cases
This section outlines some additional use cases for Embedded Cluster. These are not officially supported features from Replicated, but are ways of using Embedded Cluster that we or our customers have experimented with that might be useful to you.
NVIDIA GPU Operator
The NVIDIA GPU Operator uses the operator framework within Kubernetes to automate the management of all NVIDIA software components needed to provision GPUs. For more information about this operator, see the NVIDIA GPU Operator documentation. You can include the operator in your release as an additional Helm chart, or using the Embedded Cluster Helm extensions. For information about Helm extensions, see extensions in Embedded Cluster Config.
Using this operator with Embedded Cluster requires configuring the containerd options in the operator as follows:
toolkit:
env:
- name: CONTAINERD_CONFIG
value: /etc/k0s/containerd.d/nvidia.toml
- name: CONTAINERD_SOCKET
value: /run/k0s/containerd.sock
Troubleshoot with Support Bundles
Embedded Cluster includes a default support bundle spec that collects both host- and cluster-level information.
The host-level information is useful for troubleshooting failures related to host configuration like DNS, networking, or storage problems. Cluster-level information includes details about the components provided by Replicated, such as the Admin Console and Embedded Cluster operator that manage install and upgrade operations. If the cluster has not installed successfully and cluster-level information is not available, then it is excluded from the bundle.
In addition to the host- and cluster-level details provided by the default Embedded Cluster spec, support bundles generated for Embedded Cluster installations also include app-level details provided by any custom support bundle specs that you included in the application release.
There are different steps to generate a support bundle depending on the version of Embedded Cluster installed.
For Versions 1.17.0 and Later
For Embedded Cluster 1.17.0 and later, you can run the Embedded Cluster support-bundle command to generate a support bundle.
The support-bundle command uses the default Embedded Cluster support bundle spec to collect both cluster- and host-level information. It also automatically includes any application-specific support bundle specs in the generated bundle.
To generate a support bundle:
-
SSH onto a controller node.
noteYou can SSH onto a worker node to generate a support bundle that contains information specific to that node. However, when run on a worker node, the
support-bundlecommand does not capture cluster-wide information. -
Run the following command:
sudo ./APP_SLUG support-bundleWhere
APP_SLUGis the unique slug for the application.
For Versions Earlier Than 1.17.0
For Embedded Cluster versions earlier than 1.17.0, you can generate a support bundle from the shell using the kubectl support-bundle plugin.
To generate a bundle with the support-bundle plugin, you pass the default Embedded Cluster spec to collect both cluster- and host-level information. You also pass the --load-cluster-specs flag, which discovers all support bundle specs that are defined in Secrets or ConfigMaps in the cluster. This ensures that any application-specific specs are also included in the bundle. For more information, see Discover Cluster Specs in the Troubleshoot documentation.
To generate a bundle:
-
SSH onto a controller node.
-
Use the Embedded Cluster shell command to start a shell with access to the cluster:
sudo ./APP_SLUG shellWhere
APP_SLUGis the unique slug for the application.The output looks similar to the following:
__4___
_ \ \ \ \ Welcome to APP_SLUG debug shell.
<'\ /_/_/_/ This terminal is now configured to access your cluster.
((____!___/) Type 'exit' (or CTRL+d) to exit.
\0\0\0\0\/ Happy hacking.
~~~~~~~~~~~
root@alex-ec-2:/home/alex# export KUBECONFIG="/var/lib/embedded-cluster/k0s/pki/admin.conf"
root@alex-ec-2:/home/alex# export PATH="$PATH:/var/lib/embedded-cluster/bin"
root@alex-ec-2:/home/alex# source <(kubectl completion bash)
root@alex-ec-2:/home/alex# source /etc/bash_completionThe appropriate kubeconfig is exported, and the location of useful binaries like kubectl and the preflight and support-bundle plugins is added to PATH.
noteThe shell command cannot be run on non-controller nodes.
-
Generate the support bundle using the default Embedded Cluster spec and the
--load-cluster-specsflag:kubectl support-bundle --load-cluster-specs /var/lib/embedded-cluster/support/host-support-bundle.yaml